
Mouser: L’evoluzione del controllo vocale e audio per i dispositivi elettronici
La parola è un modo efficiente per esprimere idee e desideri. Prima dell'era industriale, gli esseri umani avevano scoperto che gli animali potevano essere addestrati a riconoscere e rispondere a dei comandi base con istruzioni su come svolgere un compito.

Assistente robotico a controllo vocale.
Il passaggio logico successivo è stato sviluppare un modo di comunicare con le macchine e comandarle, utilizzando la voce. Negli ultimi anni, l’utilizzo delle funzioni voce e audio come interfacce di controllo per i dispositivi elettronici ha acquisito popolarità, e oggi si sta evolvendo per soddisfare le aspettative degli utenti e i requisiti delle nuove applicazioni.
In questo articolo illustriamo quali sono i vantaggi delle funzioni voce e audio per il controllo degli apparecchi elettronici e delle macchine ed esaminiamo come vengono realizzati. Mostriamo inoltre in che modo è possibile integrare questa interfaccia di controllo nei dispositivi offline e come è possibile migliorare l’esperienza audio che forniscono.
Usare la voce per controllare i dispositivi elettronici
L’interazione voce-macchina produce numerosi vantaggi evidenti:
- Per gli esseri umani, la parola è una forma di comunicazione intuitiva che semplifica la trasmissione di comandi verbali.
- La comunicazione vocale è possibile anche se la persona ha gli occhi e le mani occupate. Se da una parte il controllo vocale simultaneo è conveniente, in alcune circostanze, come la guida, non è ammesso cercare di controllare un altro dispositivo con il tatto.
- La voce è uno strumento efficiente che permette di controllare le macchine, che sono in grado di ascoltare e rispondere senza bisogno di comandi complessi.
- L’integrazione della voce riduce al minimo la necessità di un touchscreen su molti dispositivi. Questo presenta grandi vantaggi soprattutto per gli apparecchi posizionati in remoto o per gli apparecchi portatili alimentati a batteria, per i quali la riduzione delle dimensioni e del consumo di energia rappresentano le sfide classiche di progetto. Eliminare il requisito del tocco risulta anche più igienico per le applicazioni con più utenti.
- Come mostrato nella figura 1, il comando vocale può essere uno strumento potente per le persone con disabilità per le quali il tocco potrebbe non essere un’opzione praticabile. La comunicazione vocale con le macchine può essere usata per svolgere compiti come aprire le porte, o comunicare a distanza aggiornamenti sullo stato di salute di una persona.
Il front end audio (AFE) di un dispositivo con controllo vocale include una matrice di microfoni e di blocchi per l’elaborazione del segnale. L’AFE elabora il segnale proveniente da una matrice di microfoni multicanale per eliminare le interferenze provenienti da rumori di fondo o dalla riproduzione da parte del dispositivo stesso. Questo segnale viene inviato a un motore di rilevamento della ‘wake word’ (parola di attivazione) che riconosce parole come “Alexa” o “OK Google,” che sono pre-programmate sul dispositivo. Algoritmi multipli di elaborazione del segnale vengono utilizzati per eliminare segnali di interferenza indesiderati. Tra i componenti di una soluzione di controllo vocale figurano:
Matrice di microfoni: I sistemi di attivazione vocale richiedono uno o più microfoni per catturare il segnale di controllo audio. Dimensione, costo, prestazioni e robustezza sono gli aspetti principali da valutare quando si sceglie una matrice di microfoni. La combinazione di segnali diversi provenienti da una matrice di più microfoni aiuta a migliorare il rapporto segnale/rumore (SNR) per la catena del segnale audio.
Rilevatore della direzione di arrivo (DoA): Viene usato per determinare la posizione dell’utente rispetto al dispositivo controllato, in modo tale che la matrice di microfoni possa puntare verso un fascio in direzione della voce.
Beamformer: Accetta i suoni dal DoA mentre respinge i suoni provenienti da altre direzioni. Le sue prestazioni dipendono dalla geometria e dal rapporto SNR della matrice di microfoni, dall’ampiezza del fascio e dal livello del rumore di fondo.
Cancellatore di eco acustico (AEC): Rifiuta il segnale di riproduzione sull’altoparlante del dispositivo stesso (ad esempio, se l’altoparlante sta riproducendo della musica) per permettere che il comando vocale dell’utente venga captato chiaramente.
Cancellatore adattivo di interferenze (AIC): Elimina il rumore esterno proveniente da altre sorgenti sonore che sono difficili da eliminare con un beamformer tradizionale, ad esempio rumori forti ad alta intensità da altri apparecchi.
Rilevatore della parola di attivazione: Il segnale vocale elaborato proveniente dall’AFE viene confrontato con una libreria di parole di attivazione come “Hey Google”, utilizzando un algoritmo di rilevamento che fa parte di un modello di apprendimento automatico. I modelli più grandi sono più accurati: ad esempio un modello addestrato da 1 MB è più accurato di un modello da 64 kB ma è più impegnativo per il processore. Per rilevare accuratamente la parola di attivazione riducendo il numero di falsi allarmi sono necessari modelli grandi.
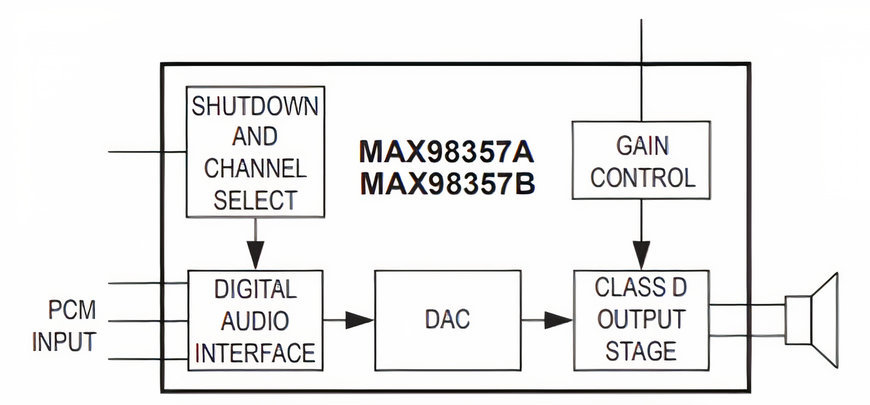
Diagramma a blocchi semplificato degli amplificatori audio di classe D di Maxim Integrated
Amplificatori audio di classe D
La sezione di elaborazione vocale di questa interfaccia di controllo ha subito un notevole sviluppo che adesso permette anche ai dispositivi a basso costo di fornire una capacità di riconoscimento vocale accurata. Tuttavia, la sezione audio dell’interfaccia ha ricevuto molta meno attenzione, il che significa che la qualità del suono prodotta da molti altoparlanti intelligenti di prima generazione e da altri dispositivi Internet-of-Things (IoT) con funzioni audio era inferiore rispetto a quella prodotta da apparecchi audio di fascia più alta.
La novità del controllo vocale è stata forse considerata una distrazione in grado di distogliere l’attenzione da questo limite. Tuttavia, con l’aumento della diffusione dei dispositivi intelligenti, stanno crescendo anche le aspettative dei clienti verso l’esperienza audio che offrono. La bassa efficienza degli amplificatori audio tradizionali di classe AB li rende poco pratici per l’utilizzo nei dispositivi IoT a bassa potenza, ma diversi produttori di chip recentemente hanno introdotto una gamma di amplificatori audio di classe D all'avanguardia che costituiscono un significativo miglioramento rispetto a quelli disponibili in precedenza. Molti di questi sono stati sviluppati appositamente per offrire un segnale audio di alta qualità nei dispositivi intelligenti e nei dispositivi IoT.
L’amplificatore audio TAS2770 da 15 W di Texas Instruments aumenta il volume e la qualità dell’audio, mentre la sua accresciuta capacità di catturare la voce si traduce in un funzionamento più semplice e naturale dei dispositivi con controllo vocale. È il primo front end audio a combinare un ingresso microfono digitale con un potente amplificatore di rilevamento I/V, che permette di captare la voce e i rumori dell'ambiente per l’eliminazione dell’eco o la riduzione del rumore nelle applicazioni a comando vocale.
Maxim Integrated (adesso parte di Analog Devices) ha progettato gli amplificatori di classe D MAX98357 e MAX98358 con un'efficienza del 92% e prestazioni audio d 3.2 W in classe AB. La figura 2 mostra un diagramma a blocchi semplificato per questi amplificatori. Il PAM8106 di Diodes Incorporated è caratterizzato da un consumo energetico ridotto, che ne permette l'utilizzo ottimale nei dispositivi alimentati da batterie al piombo da 1.5 V e da batterie agli ioni di litio da 3.5 V. L'amplificatore ha un'efficienza del 92% e può essere realizzato senza richiedere un ingombrante dissipatore di calore in un’architettura con formato compatto.

Soluzione di controllo vocale offline SLN-LOCAL2-IOT di NXP
Controllo vocale offline
Le soluzioni basate su cloud come Alexa di Amazon e Google Assistant sono facilmente disponibili per i dispositivi con una connessione internet stabile, ma per quelli con connettività scarsa o assente è preferibile una soluzione con controllo vocale offline. Ad esempio, se un prodotto deve rispondere a semplici comandi di una sola parola come vai, arresta, ripristina, etc. (comunemente noto come keyword spotting), ha senso che l’elaborazione venga effettuata localmente sul dispositivo stesso.
La realizzazione di un semplice sistema di comando tramite parola chiave è possibile utilizzando un microcontrollore embedded a basso costo, come ad esempio la soluzione NXP basata su MCU EdgeReady per il controllo vocale locale offline. Quest'ultima utilizza il crossover MCU i.MX RT e permette agli sviluppatori di aggiungere rapidamente il controllo vocale ai propri prodotti. La soluzione NXP basata su i.MX RT106S include il kit di sviluppo SLN-LOCAL2-IOT mostrato in figura 3.
La soluzione è fornita conun software completamente integrato che gira su FreeRTOS e con un kit di sviluppo software (SDK) per permettere un rapido proof of concept. Questa soluzione permette ai produttori di aggiungere facilmente il controllo vocale ai prodotti per la casa intelligente, agli elettrodomestici, negli edifici e nelle fabbriche, senza richiedere la connettività Wi-Fi o cloud.
Il controllo vocale offline aiuta anche a risolvere i problemi di privacy di molti consumatori che temono che il proprio sistema possa essere vulnerabile alle intrusioni online. Il kit è dotato anche di un tool basato su Windows™ che può essere usato per creare modelli vocali per più di cento comandi personalizzati e numerose parole di attivazione da immissione di testo in oltre quaranta lingue.
Conclusioni
La voce e l’audio stanno rapidamente diventando le interfacce preferite in molti dispositivi intelligenti, ma sono particolarmente adatte per l’utilizzo nei dispositivi a bassa potenza e nei dispositivi IoT portatili perché non richiedono display digitali, che consumano molta energia. Molti sistemi di prima generazione erano caratterizzati da una qualità audio inferiore e potevano essere implementati solo usando una soluzione con connettività cloud.
Una nuova generazione di amplificatori audio di classe D ad alta efficienza consente oggi ai produttori di fornire apparecchi garantiscono ai consumatori un’esperienza audio di alta qualità. Sono sorte anche soluzioni che consentono di controllare i dispositivi con connettività internet scarsa o assente. Queste innovazioni dimostrano la capacità di questa tecnologia di adattarsi alle nuove esigenze che emergono, a mano a mano che le persone si abituano a questa interfaccia di controllo, e la tendenza è destinata a continuare.
www.mouser.com
Richiedi maggiori informazioni…
